Part 5: Terraform - Code Structuring
In this part of the series, we look at approaches to structuring terraform code.
As usual, if you haven't read the previous parts I have linked them below.
- Part 1: Terraform – Getting Started
- Part 2: Terraform – Fundamentals
- Part 3: Terraform – Installation
- Part 4: Terraform – Configuration Files
This post assumes requisite knowledge of networking. To maintain a better flow, it is also highly recommended to read the previous posts for a background on terraform.
In this post
- What factors can determine code structure?
- What problem are we trying to solve with this code?
- Steps to create environment
- Diagram of resource dependencies and relationships
- Types of resources in the cloud
- Terraform community suggested code structure
- What does each file in the hierarchy do or contain?
- Deploying part of the infrastructure
We start with a clear statement. There is no one size fits all approach regarding how to structure a terraform code repository!
What factors can determine code structure?
Sometimes it may make sense to write all of the code in one file. Other times, it may provide flexibility to disperse the component configurations into different files in a directory. For more complex projects, it may make sense to have multiple directories and use a modules approach referencing each other.
The optimal structure to use will depend on a variety of factors like:
- the scope of the project
- the complexity of the project
- the purpose of the code
- collaboration requirements between teams
- how often the code changes, and so on.
To illustrate this, let's look at the following practical scenario.
We need to create an AWS infrastructure which is represented by the diagram below:
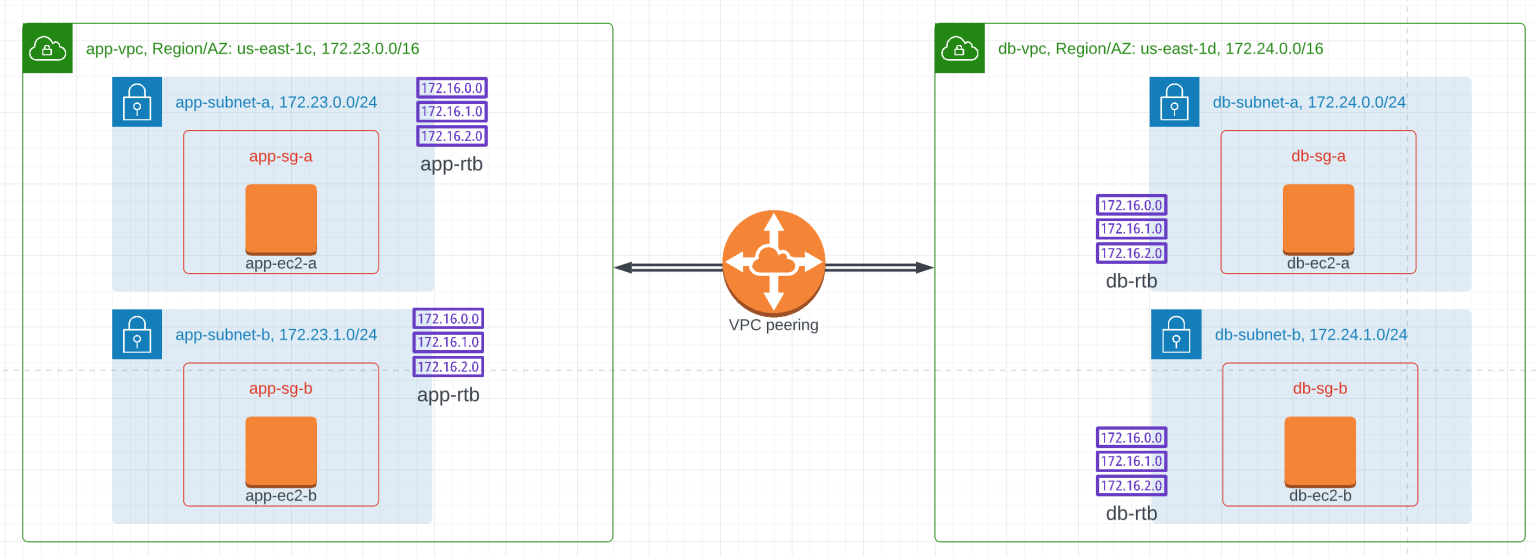
There are two VPCs: application and database VPCs. Inside each VPC, we have two subnets. app-subnet-a hosts resources for one application and app-subnet-b hosts resources for a different application. The database counterparts of these applications reside in a different VPC and availability zone.
This is not an actual design. In the real world, you'd typically choose to deploy the application and database resources in a redundant manner and in multiple availability zones.
- We are tasked to ALLOW "subnet-a-to-subnet-a" or "subnet-b-to-subnet-b" communication across the peering. Application servers on the left can communicate with their database counterparts on the other side.
- We are tasked to DENY "subnet-a-to-subnet-b" or "subnet-b-to-subnet-a" communication across the peering. Application servers on the left cannot access databases that do not correspond to them.
A couple of options we can consider to accomplish this traffic isolation requirement:
- We have a single route table shared by the subnets in each VPC (either app-rtb or db-rtb). For that reason, our capability to implement traffic isolation on a routing level is limited.
- A convenient place to implement the traffic permit/deny requirement is by using rules on the security groups attached to the EC2 instance network interfaces.
What are the steps we need to take to create this environment?
As you plan your infrastructure deployment project, you will start seeing dependencies or relationships among resources. For example, you cannot put an EC2 instance in a subnet that does not exist. You cannot peer a VPC with a VPC that doesn't exist. And so on.
Consider the provisioning steps for the application VPC i.e. app-vpc
- Create the VPC.
- Inside the VPC, create subnets.
- Inside the VPC, create a route table. Inside the route table, create routes.
- Inside the VPC, create security groups. Inside the security group, create rules.
- Inside the VPC, create network interfaces.
- Inside the subnets, create ec2 instances.
- Attach security group(s) with the network interface(s),
- Attach network interface(s) with the ec2 instances.
- Associate the subnets with the route table.
These steps need to be repeated for the database VPC and its resources on the right i.e. db-vpc
Finally, once the two VPCs exist, a VPC peering connection needs to be created between them.
I think flow- and finite-state machine diagrams are cool. So, this is to pictorially represent a simplified version of what it would look like for a VPC and its resources.
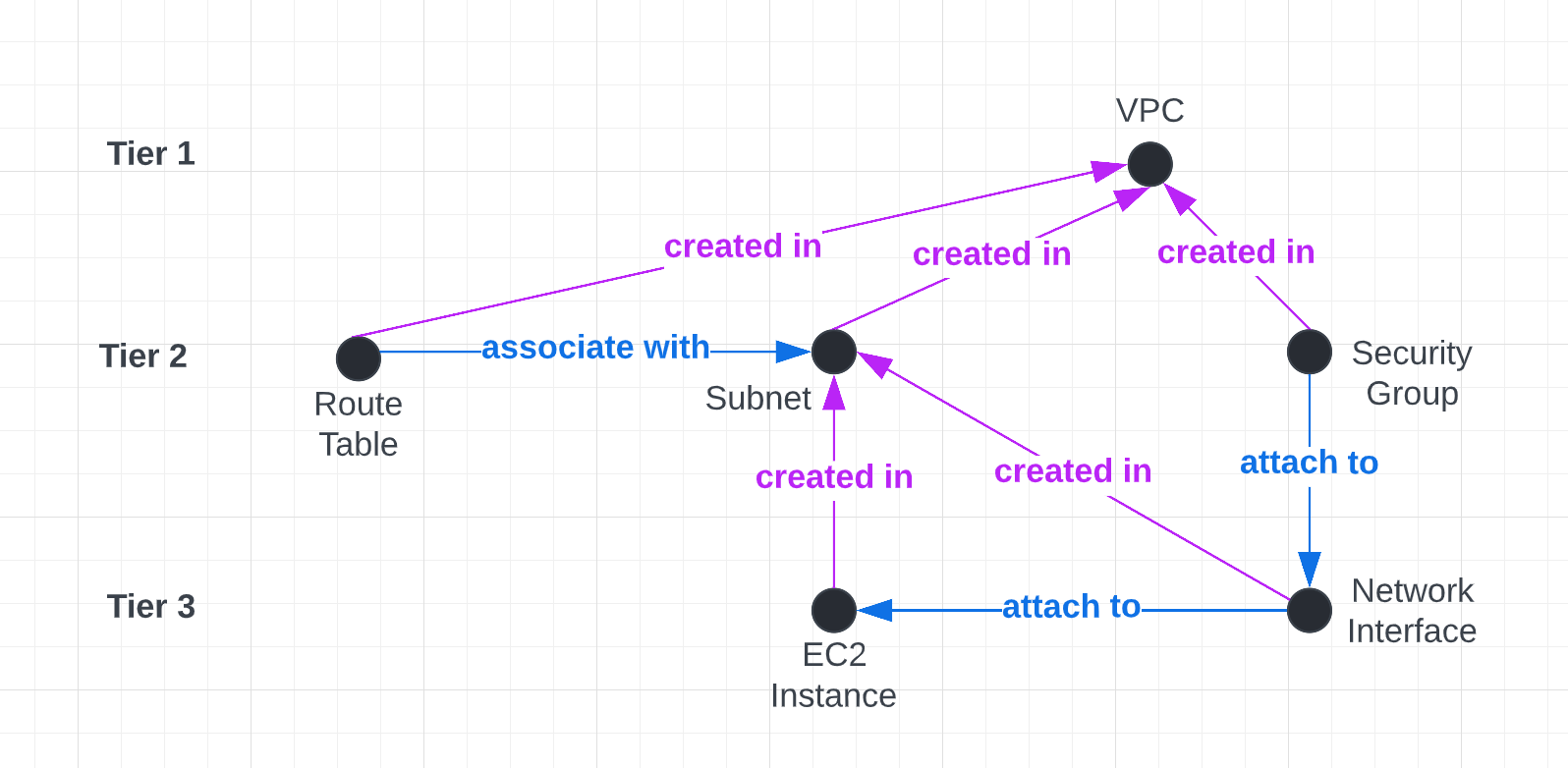
As far as I've seen, AWS and other cloud providers do not describe them as such but it helps me to think of resources as Tier 1, Tier 2, Tier 3, etc.
- Tier 1 resources: These don't depend on any other resources for their creation step. (Assuming you have an account, admin privileges, and all that already)
- Tier 2 resources: To be created, these resources depend on existence of Tier 1 resources such as a VPC.
- Tier 3 resources: To be created, these resources depend on more than one tier of resources.
Suggested Code Structure
As a general guideline, this hierarchy is one way the Terraform community suggests to organize files in a working directory.
.
├── LICENSE
├── locals.tf
├── main.tf
├── outputs.tf
├── providers.tf
├── README.md
├── resources.tf
├── changing.tfvars
├── variables.tf
What does each file in the hierarchy do or contain?
- LICENSE: Specify the license model for the code here. Could be open source or other type.
- Variables: Variables are just symbolic names which serve as memory placeholders for values. There are few types of variables in Terraform (local, input, output, and environment)
- Local variables: These are constants that cannot be overridden during a terraform run. Once declared, they can be re-used throughout the code. Typically, these can be placed in a separate locals.tf file made up of a local or locals block. Defining them as named values once improves code readability since they don't have to be typed out in long form for every occurrence in the code.
- Input variables: In contrast to local variables, the default values of these variables (if they have one) can be overridden by other special variable files or by interaction with the command line. These can be placed in a variables.tf file. If we have future infrastructure value modifications to make, we focus on updating this file instead of needing to interact with every file in the code repository.
- Output variables: These are useful to define what you want to see on the screen as terraform plans, applies, or destroys infrastructure. You define variables that store values. If you are familiar with C++ and Python, you can also think of it as a parallel to the return method. We can represent these functionalities in an outputs.tf file.
- Environment variables: In a previous blog post, remember when we said there needs to be a better way to manage credentials instead of using them in a text file? The environment variables approach will allow us to do this along with many other capabilities. We'll use this below for authentication.
- main.tf: This can be used to set the stage such as backend and plugin configurations.
- providers.tf: It is possible to declare provider plugins in a separate file. This may be relevant if there are multiples of them to be declared.
- README.md: This is a file whose purpose is to describe what the project is about, what it is supposed to solve, how users should approach the code, and so on.
- resources.tf: This can be used as a place to define resources. Or this file can also be split in to multiple different files based on function, type, geography, or whatever other criteria that makes sense for the project.
- changing.tfvars: This file can be used to host special variables that we want to use on each terraform run. Depending on if we are provisioning the app or db infrastructures in the diagram above, we change the values to reflect that. Then we tell terraform to plan or apply based on the contents of this file.
If some of these descriptions are not quite clear yet, read on. They will be through the practical exercise.
What if we don't use this sort of file structuring? The configuration files can become bloated, introduces risk of error, and gets costly to maintain in the long term. Do we have to use the exact same structure suggested above? No, we can leave out the files that we believe do not provide value based on our code planning and algorithmic thinking.
To build the AWS infrastructure in the diagram above, we can structure our files in different ways. This is where subjectivity plays a big role. For example:
- Option 1: We could organize network resources in one file and compute resources in another. This is organizing resources by their function type. We can choose to ignore the LICENSE file because this is a small project. We can eliminate providers.tf from the list and declare provider plugins inside the main.tf file. We can choose to skip the README file too.
.
├── main.tf
├── outputs.tf
├── network.tf
├── compute.tf
├── changing.tfvars
├── variables.tf
- Option 2: Resource tier identification can be a laboring process but helps with a framework to think about how resources are organized in the cloud. Even though I wouldn't recommend it for structuring files, there's nothing that prohibits us from doing so other than good design sense. We can explicitly state the licensing plans for the code. We can leave out the provider plugin declaration in its own file.
.
├── LICENSE
├── main.tf
├── outputs.tf
├── providers.tf
├── README.md
├── tier1.tf
├── tier2.tf
├── tier3.tf
├── changing.tfvars
├── variables.tf
Let’s start very simple so the descriptions come across clearly and we build up the infrastructure block by block.
We zoom in on how to create the VPCs and the subnets inside them.
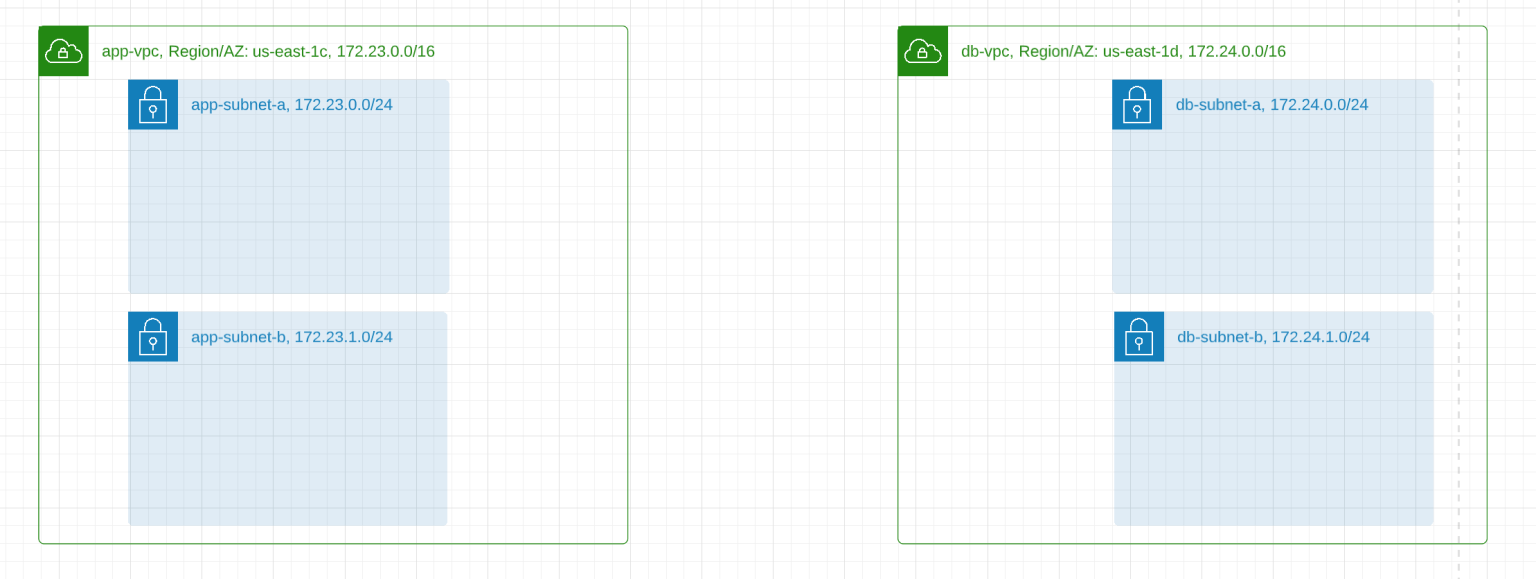
Provisioning parts of the infrastructure
- Prepare a working directory and name it vpc-peering-project
- Inside the vpc-peering-project directory, create a variables.tf file. Define the variables.
variable "aws_region" {
description = "AWS region"
type = string
}
//App VPC Variables
variable "app_az" {
description = "Availability Zone"
type = string
}
variable "app_env_prefix" {
description = "tag, name, or description prefix"
type = string
}
variable "app_subnet_name" {
description = "subnet name"
type = list(string)
}
variable "app_vpc_cidr" {
description = "VPC CIDR block"
type = string
}
variable "app_subnet_cidr" {
description = "Subnet CIDR block"
type = list(string)
}
//DB VPC Variables
variable "db_az" {
description = "Availability Zone"
type = string
}
variable "db_env_prefix" {
description = "tag, name, or description prefix"
type = string
}
variable "db_subnet_name" {
description = "subnet name"
type = list(string)
}
variable "db_vpc_cidr" {
description = "VPC CIDR block"
type = string
}
variable "db_subnet_cidr" {
description = "Subnet CIDR block"
type = list(string)
}- Inside the vpc-peering-project directory, create a main.tf file with code
# Declare terraform provider plugin
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 3.0"
}
}
}
# Provider
provider "aws" {
region = var.aws_region
}- Inside the vpc-peering-project directory, create a network.tf file
// This section of code provisions the Application VPC
// env_prefix=app, az=us-east-1c, vpc_cidr=172.23.0.0/16
// subnet-a is 172.23.0.0/24, subnet-b is 172.23.1.0/24
# Create app VPC
resource "aws_vpc" "app-vpc" {
cidr_block = var.app_vpc_cidr
tags = {
Name = format("%s-%s", var.app_env_prefix, "vpc")
}
}
# Create app-subnet-a
resource "aws_subnet" "app-subnet-a" {
vpc_id = aws_vpc.app-vpc.id
cidr_block = var.app_subnet_cidr[0]
availability_zone = var.app_az
tags = {
Name = format("%s-%s", var.app_env_prefix, var.app_subnet_name[0])
}
}
# Create app-subnet-b
resource "aws_subnet" "app-subnet-b" {
vpc_id = aws_vpc.app-vpc.id
cidr_block = var.app_subnet_cidr[1]
availability_zone = var.app_az
tags = {
Name = format("%s-%s", var.app_env_prefix, var.app_subnet_name[1])
}
}
// This section of code is for the Database VPC
// env_prefix=db, az=us-east-1d, vpc_cidr=172.24.0.0/16
// subnet-a is 172.24.0.0/24, subnet-b is 172.24.1.0/24
# Create db VPC
resource "aws_vpc" "db-vpc" {
cidr_block = var.db_vpc_cidr
tags = {
Name = format("%s-%s", var.db_env_prefix, "vpc")
}
}
# Create db-subnet-a
resource "aws_subnet" "db-subnet-a" {
vpc_id = aws_vpc.db-vpc.id
cidr_block = var.db_subnet_cidr[0]
availability_zone = var.db_az
tags = {
Name = format("%s-%s", var.db_env_prefix, var.db_subnet_name[0])
}
}
# Create db-subnet-b
resource "aws_subnet" "db-subnet-b" {
vpc_id = aws_vpc.db-vpc.id
cidr_block = var.db_subnet_cidr[1]
availability_zone = var.db_az
tags = {
Name = format("%s-%s", var.db_env_prefix, var.db_subnet_name[1])
}
}- Inside the vpc-peering-project directory, create a changing.tfvars file
aws_region = "us-east-1"
app_az = "us-east-1c"
app_env_prefix = "app"
app_subnet_name = ["subnet-a", "subnet-b"]
app_vpc_cidr = "172.23.0.0/16"
app_subnet_cidr = ["172.23.0.0/24","172.23.1.0/24"]
db_az = "us-east-1d"
db_env_prefix = "db"
db_subnet_name = ["subnet-a", "subnet-b"]
db_vpc_cidr = "172.24.0.0/16"
db_subnet_cidr = ["172.24.0.0/24", "172.24.1.0/24"]At this point, your working directory should look like this:
.
├── main.tf
├── network.tf
├── changing.tfvars
├── variables.tf
Ok. let's run this and provision these VPCs and their subnets.
- First, we need to get situated in the terraform directory. Change directory to vpc-peering-project
- Next we need to pass our credentials so that Terraform can make use of them. We do that by using the environment variables we mentioned above instead of saving sensitive information in text file.
- In a previous post we saw how to create a user account that has programmatic access. You should have the access key and secret key saved from that. The commands we will be entering one after the other are:
export AWS_ACCESS_KEY_ID="your_access_key"
export AWS_SECRET_ACCESS_KEY="your_secret_key"
export AWS_DEFAULT_REGION="aws_region"
- Then we initialize terraform using terraform init. Terraform will initialize, download provider plugins if it needs to do that, and return with a successful message.
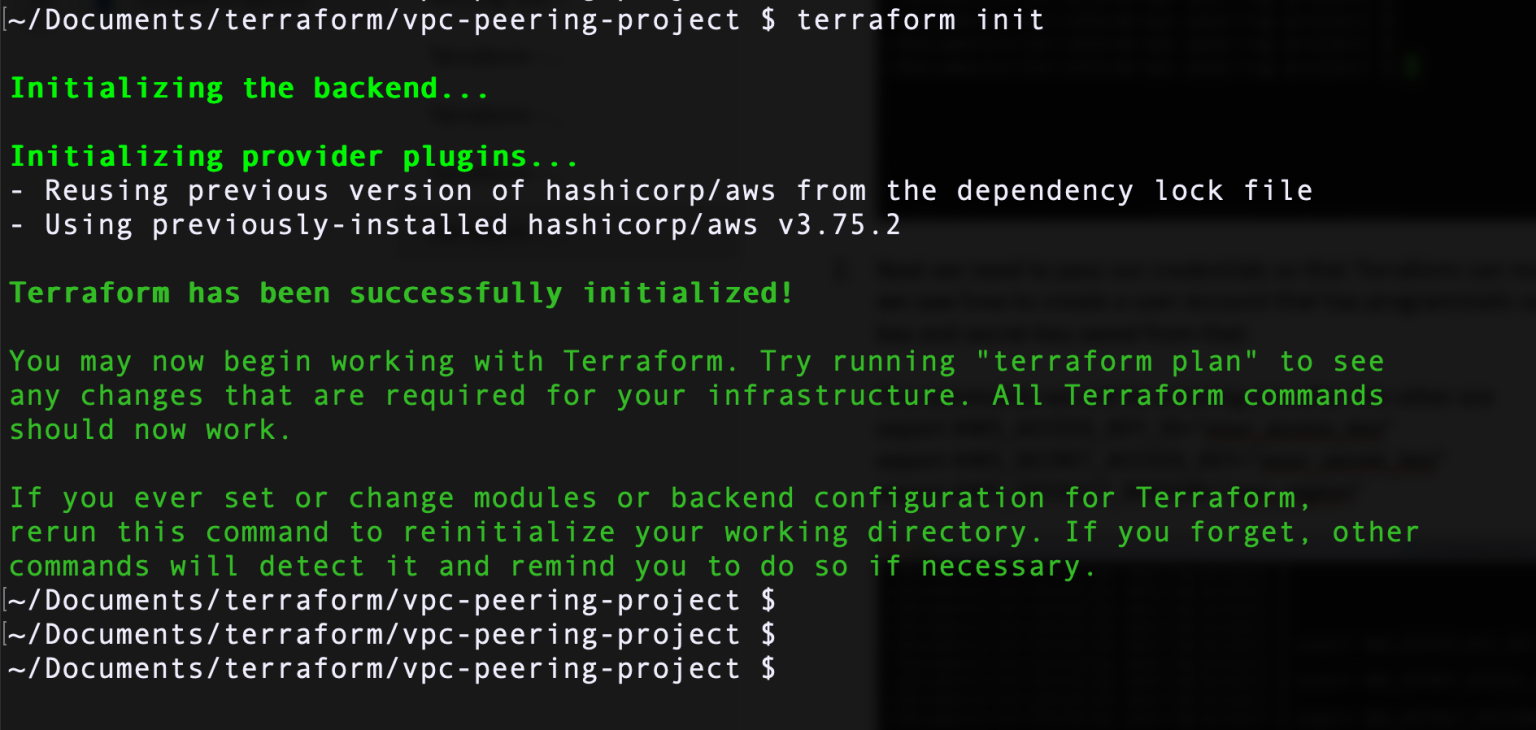
- To plan our terraform deployment, we will use the changing.tfvars file as an input, Terraform reads through the variables and values we defined in changing.tfvars file. Instead of just terraform plan, the command to use will be terraform plan -var-file=changing.tfvars
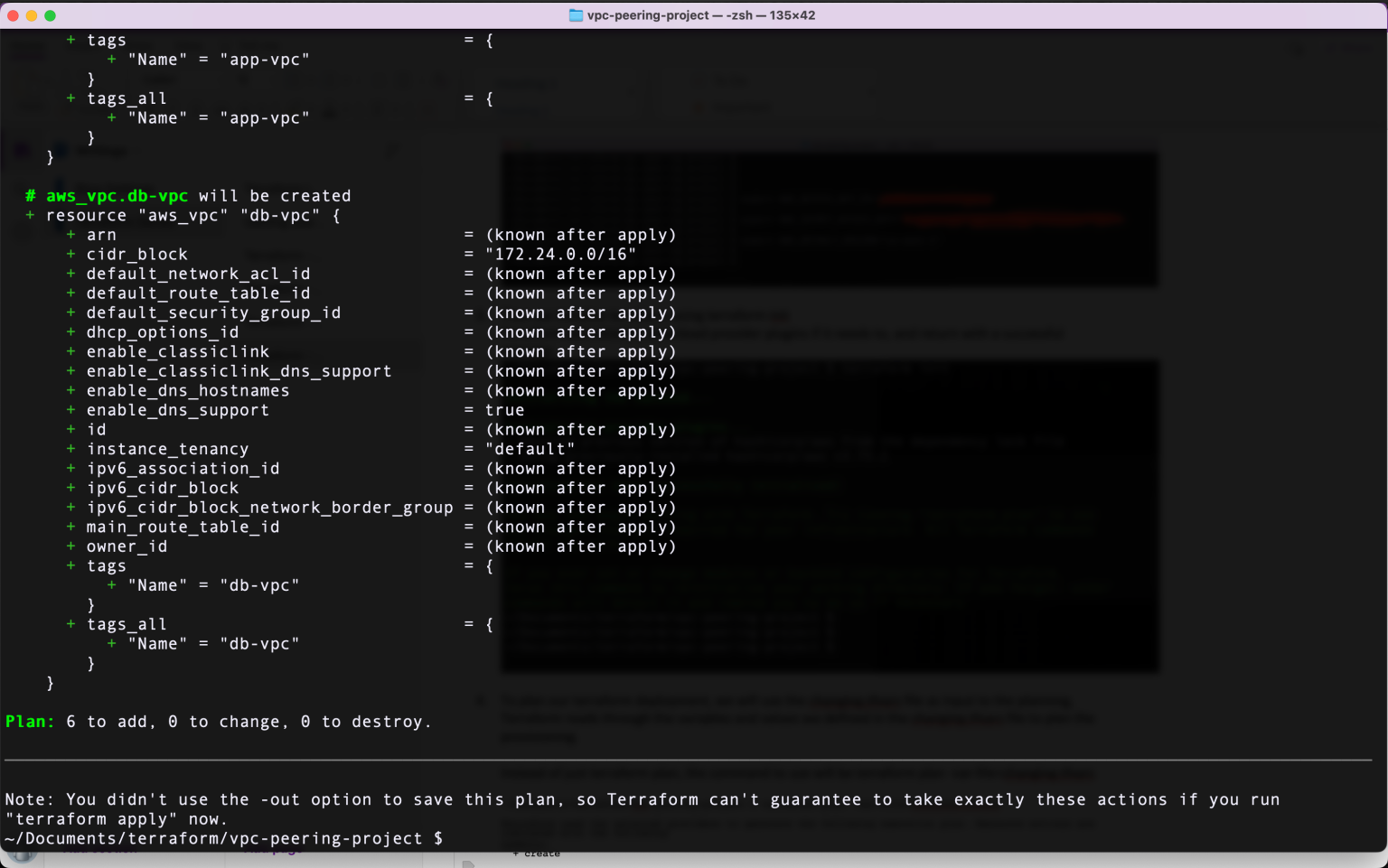
The partial output will look like in the picture above. Terraform says it will add 6 resources i.e. two VPCs and four subnets. As you run the code, look through the output to see what values it will change.
- To apply the code, we issue terraform apply -var-file=changing.tfvars The partial output after a successful apply will return an output similar to the following
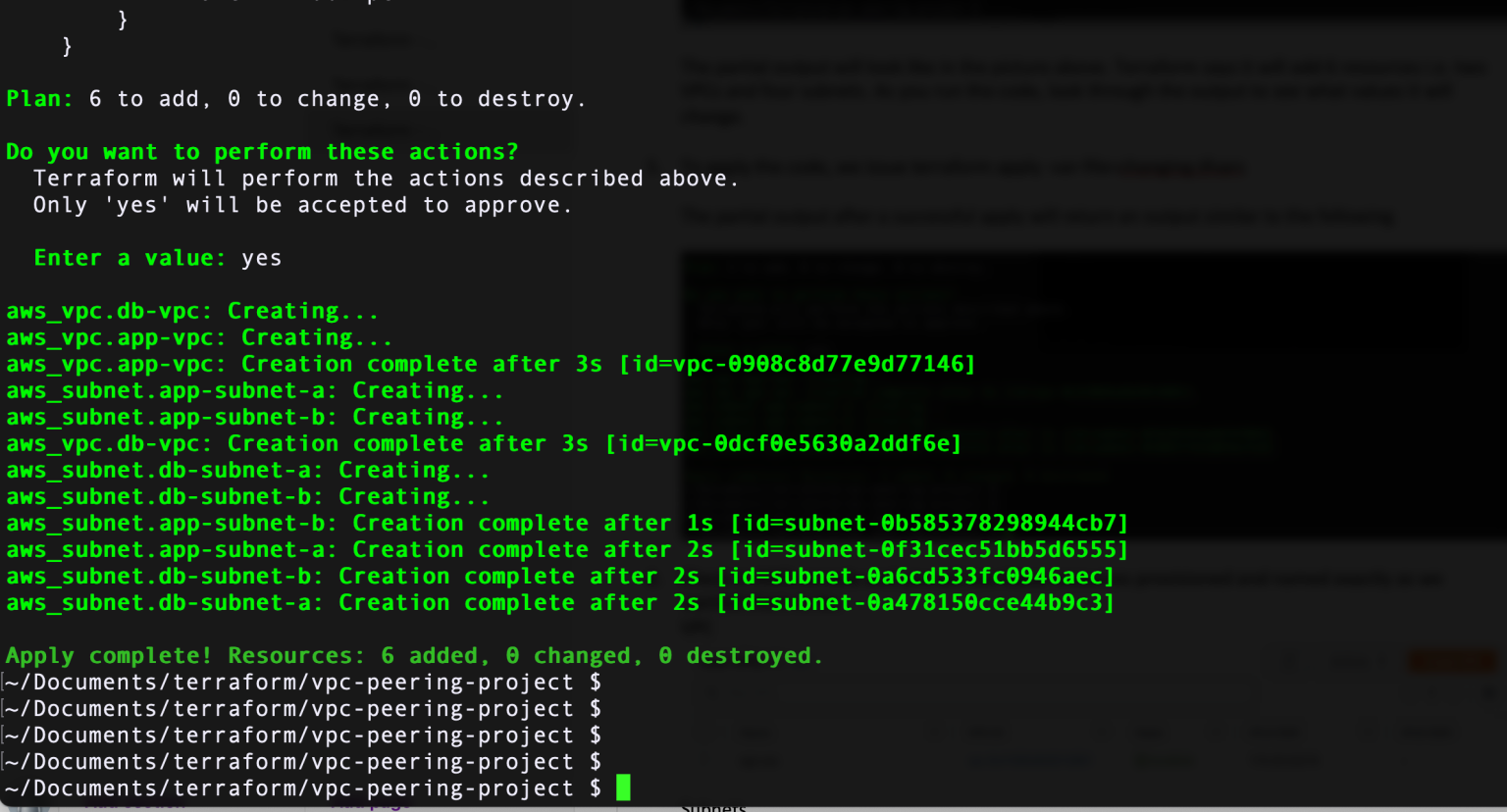
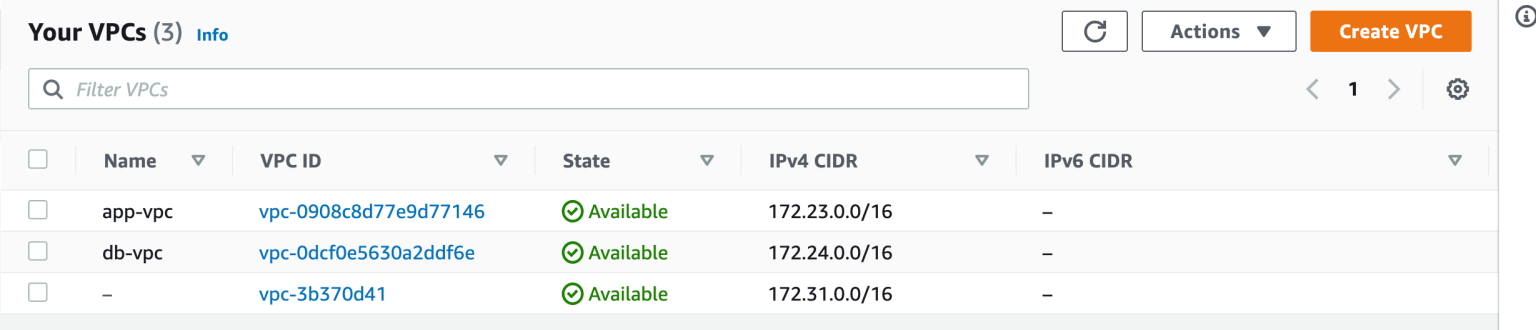
- Check in AWS console and you will see these resources provisioned and named exactly as we wanted them to be.

- To destroy the infrastructure, use the command terraform destroy -var-file=changing.tfvars
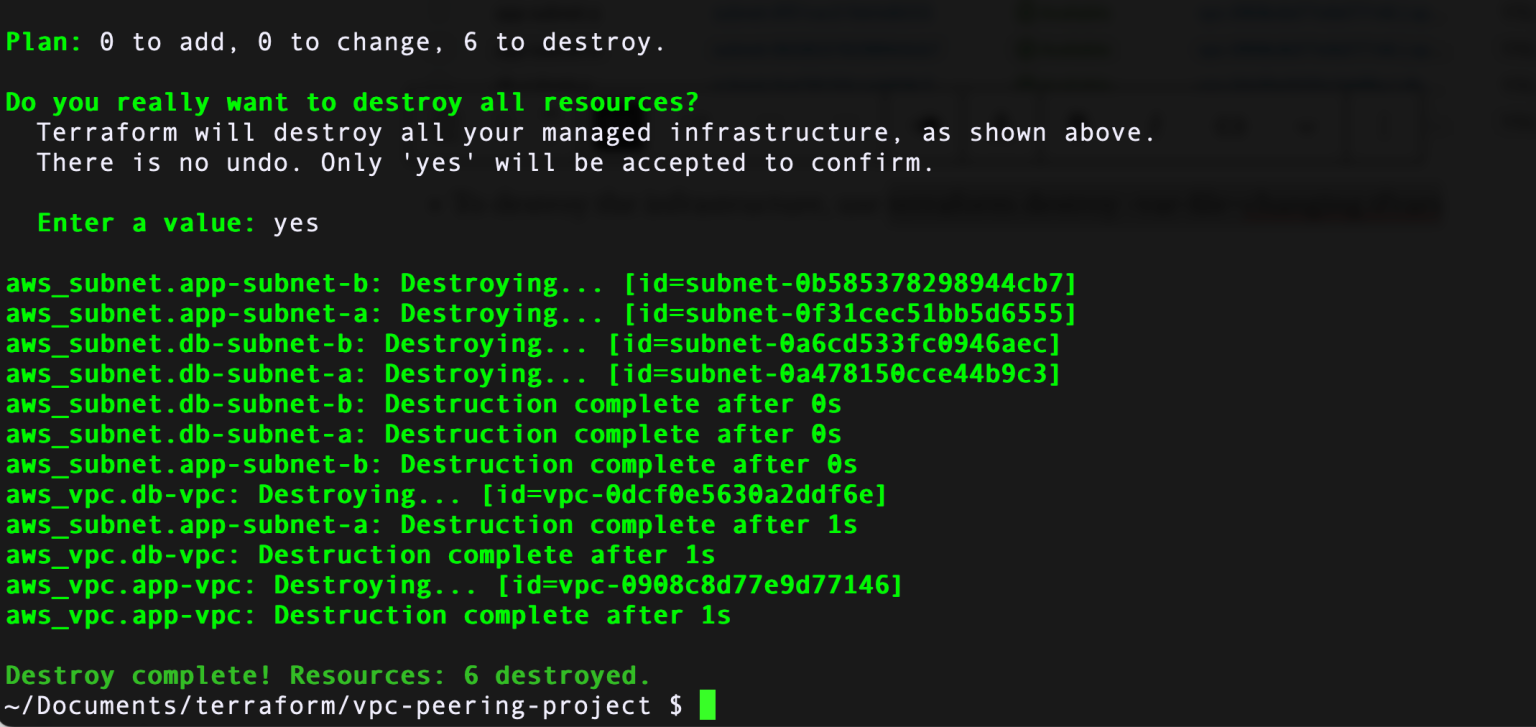
- They will disappear in the AWS console.
If you review the code again, you can see that there are many lines that we can eliminate in order to optimize it. There are constant elements that lend themselves well to the usage of a locals.tf file. If we use list(string) type variables, we will have to rely on array references in the form of variable_name[0] or variable_name[1] to locate a value. This can make the code shorter but may reduce code readability in the long run.
So, in this case one subjective perspective could be to say "longer is better than an unreadable code." Trade offs like this (code-length vs code-readability) are what make code structures inevitably differ. It is not an exact science.
In upcoming posts, we will continue building out this topology to incorporate other terraform concepts and validate that we accomplish our stated traffic isolation objectives.
Tags: aws, terraform
← Back home